RRI Digital Archive System
A digital archive management system for RRI Banjarmasin featuring automatic OCR and AI-based document classification. Built with a microservice architecture combining Laravel, React, and Python FastAPI.
Screenshots
Application Preview
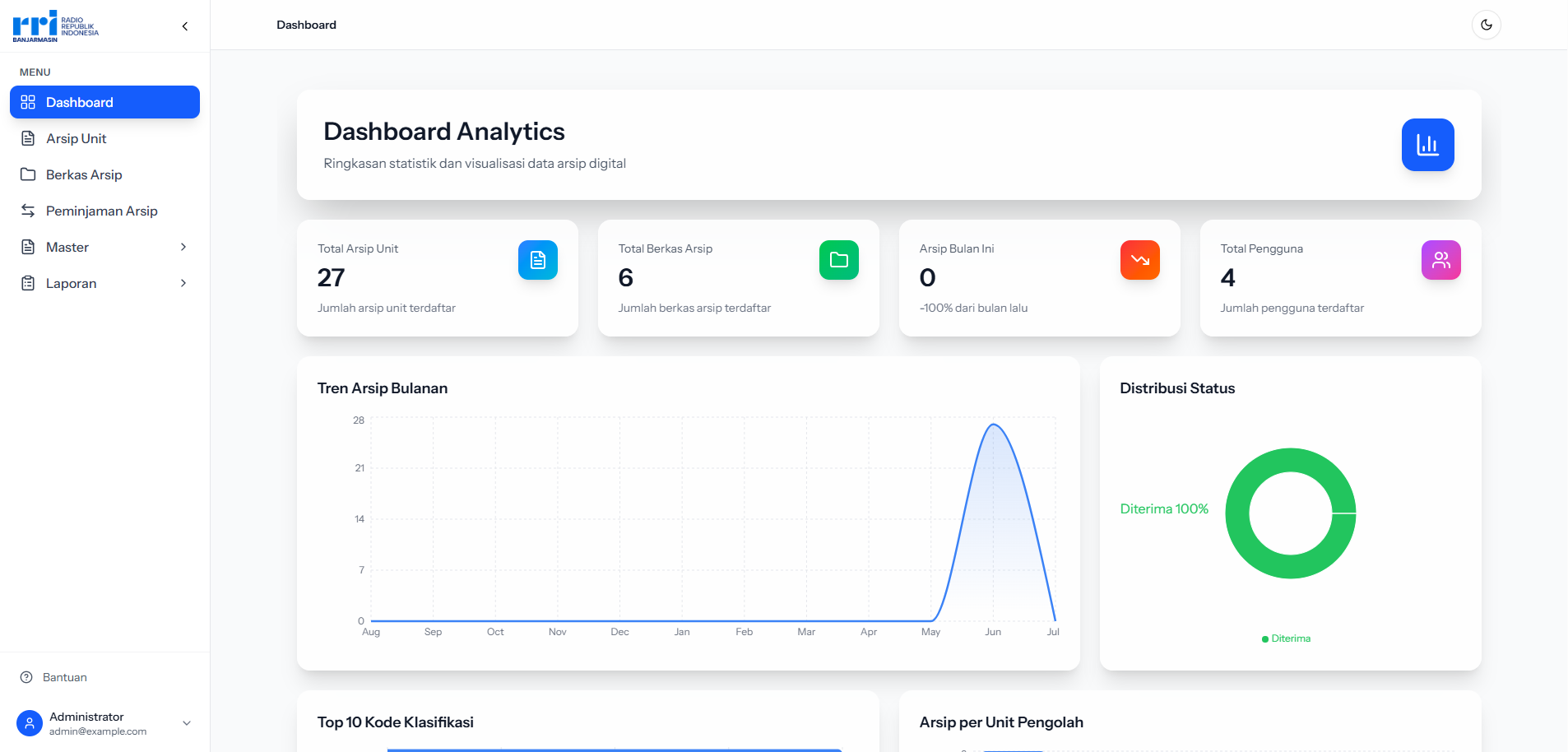
Dashboard Analytics — Dashboard with monthly trend charts, status distribution, top classifications, and OCR statistics
Capabilities
Key Features
Archive Unit Management
Full CRUD for archive documents with file upload, comprehensive metadata, and multi-stage verification workflow (pending → accepted/rejected → published).
Archive File Management
Group archive units into archive files with retention and disposal information tracking.
OCR (Optical Character Recognition)
Automatic text extraction from PDF/image documents using Tesseract via Python microservice with OpenCV preprocessing.
AI Classification
Automatic document category prediction using TF-IDF + Multinomial Naive Bayes (scikit-learn).
Role-Based Access Control
3 access levels: Admin, Operator, User with 32+ granular permissions for data security.
Dashboard Analytics
Real-time monthly trend charts, status distribution, top classifications, and OCR statistics.
Activity Logging
Complete audit trail with before/after value comparison for every data change.
Two-Factor Authentication
Enhanced security with TOTP (Time-based One-Time Password) and recovery codes.
Reports & PDF Export
Disposal reports, verification status, handover documents, and processing unit summaries.
Architecture
System Architecture
A microservice architecture that separates frontend, backend, and OCR service for scalability and maintainability.
Frontend
Backend
OCR Microservice
Database
Technologies
Tech Stack
Backend
Frontend
OCR Microservice
Database
CI/CD
Interested in this project?
Check out the full source code on GitHub or get in touch to discuss more about this project.